PhotoShop 傳統修圖與 AI 降噪的硬體選購指南
Published:Updated:
本文目標是告訴你怎麼挑選 PhotoShop 硬體,讓每一分錢都花的值得。
傳統修圖
PhotoShop,或者說 Adobe LR/PS 這幾個圖片編輯工具,在傳統非 AI 應用上都極度依賴 CPU 單核心性能,多核對他沒有太大幫助,因此不使用 AI 工具的情況下應該選單核心性能強勁的 CPU。
結論:Intel i5 或是現在稱作 Core Ultra 5 就是最高性價比選擇。有錢當然上 Ultra 7/9 沒問題,不過論性價比 Ultra 5 肯定最高。
AI 修圖
先搞清楚你的 AI 修圖是本地運行版本還是雲端版本,比如 AI denoise 降躁、Neural Filters 功能都屬於本地運行,圖像生成則可能是雲端服務,用到雲端的當然就不用管本地硬體。
如果是本地任務那就需要更新硬體,使用 AI 就需要用到 GPU 顯示卡處理,因此直接上表格:
| 執行時間(秒) | CPU | GPU | RAM |
|---|---|---|---|
| 16 | i9-14900K | RTX4090 | 96GB DDR5-RAM |
| 20 | R9 7950X3D | RTX4090 24GB | 64GB DDR5-RAM |
| 20 | R9 5950X | RTX3090 24GB | 32GB DDR4-RAM |
| 26 | R9 3900X | RTX4090 24GB | 64GB RAM |
| 28 | R9 5900X | RTX4080 Super 16GB | 64GB DDR4-RAM |
| 30 | i7-14700K | RTX4070 Ti 12GB | 96GB DDR5-RAM |
| 30 | i9-12900K | RTX4070 Ti 12GB | 64GB DDR5-RAM |
| 30 | i5-12600K | RTX3080 10GB | 32GB DDR4-RAM |
| 30 | R9 5900X | RTX3080 Ti | 32GB DDR4-RAM |
| 30 | R7 7800X3D | RX7900XTX | 32GB DDR5-6000 |
| 32 | i7-13700K | RX7900XTX | 64GB DDR5-RAM |
| 32 | Threadripper 1950X | RTX4080 | 64GB DDR4-RAM |
| 32 | R7 5800X3D | RTX3080 Ti | 32GB DDR4-RAM |
| 32 | R7 5700X | RTX3080 12GB | 32GB DDR4-RAM |
| 36 | i9-9900K | RTX3080 10GB | 64GB RAM |
| 36 | i5-13600K | RTX4070 12GB | 64GB DDR4-RAM |
| 36 | i7-13700K | RTX4070 12GB | 64GB DDR5-RAM |
| 36 | i7-14700KF | RTX4070 12GB | 64GB DDR5-RAM |
| 36 | R9 5900X | RTX3070 8GB | 64GB DDR4-RAM |
| 36 | Apple M2 Ultra 24CPU | Apple M2 Ultra 60GPU Cores | 64GB RAM |
| 38 | R9 5900X | RTX4070 12GB | 64GB DDR5-RAM |
| 40 | Apple Mac Studio M1 Ultra | Apple M1 Ultra | 64GB RAM |
| 40 | i7-9700K | RTX4070 12GB | 64GB RAM |
| 40 | R9 5900X | RX6900XT | 32GB DDR4-RAM |
| 40 | R9 7900RX | RX7900X | 64GB DDR5-RAM |
| 42 | i9-12900F | RTX3070 8GB | 32GB RAM |
| 42 | i5-12600K | RTX3070 8GB | 32GB DDR4-RAM |
| 44 | i7-13700K | RTX4060 Ti 8GB | 64GB DDR5-5600 |
| 44 | i9-11900K | RTX3060 Ti 8GB | 64GB RAM |
| 46 | i7-13700 | RTX4060 16GB | 128GB |
| 46 | i9-9900K | RX7800XT 16GB | 32GB RAM |
| 46 | R7 5800X OC | RX6900XT OC | 32GB DDR4-RAM |
| 48 | R7 3800X | RTX3060 Ti 8GB | 32GB RAM |
| 50 | R9 7950X | RTX4060 8GB | 96GB DDR5-RAM |
| 50 | i9-9900 | RTX2080 Super | 32GB RAM |
| 52 | R7 7840HS | RTX4060 8GB | 16GB DDR5-RAM |
| 54 | i9-12900K | RTX3060 12GB | 32GB DDR4 |
| 54 | i7-13700K | RTX3060 12GB | 64GB DDR5-5600 |
| 54 | i7-12700 | RTX3060 12GB | 64GB DDR4-RAM |
| 54 | i5-13600K | RTX4060 8GB | 32GB RAM DDR5 |
| 56 | i9-13900 | RTX3060 12GB | 32GB DDR5-RAM |
| 56 | R9 5900X | RTX3060 12GB | 32GB DDR4-RAM |
| 56 | R7 5700X | RX6800 | 32GB DDR4-RAM |
| 56 | i7-13700H | RTX4070 8GB Mobile | 16GB DDR5-RAM |
| 58 | MacBook Pro M2 Max | Apple Pro M2 Max (30 GPU) | 64GB RAM |
| 58 | MacBook Pro M2 Max | Apple Pro M2 Max (38 GPU) | 32GB RAM |
| 58 | R9 3900X | RTX3060 12GB | 64GB DDR4-RAM |
| 58 | R5 3600 | RTX2070 Super 8GB | 32GB DDR4-RAM |
| 58 | i7-13700H | RTX4060 8GB Mobile | 32GB RAM |
| 58 | i7-12700H | RTX3060 6GB Mobile | 16GB RAM |
| 60 | i9-9900K | RTX3060 12GB | |
| 60 | MacBook Pro M1 Max | Apple Pro M1 Max | 64GB RAM |
| 62 | MacBook Pro M1 Max | Apple Pro M1 Max | 64GB RAM |
| 66 | R9 5900X | Quadro RTX4000 8GB | 64GB DDR4-RAM |
| 70 | Xeon E5-2696 v4 | Quadro RTX4000 8GB | 64GB DDR4-RAM |
| 70 | Mac Studio | Apple M1 Max | 32GB RAM |
| 70 | R5 5600G | RTX3050 8GB | 32GB DDR4-RAM |
| 70 | i7-13700K | RTX2060 6GB | 32GB DDR5-RAM |
| 76 | R9 5900X | RX6700 XT 12GB | 128GB DDR4-RAM |
| 86 | Mac i7-4790K | RX6600 Pulse | 32GB RAM |
| 86 | R7 5800X | RX6700 XT 12GB | 32GB RAM |
| 88 | R7 7840HS | RX6650M 8GB Mobile | 24GB RAM |
| 90 | i7-12850HX | RTX-A1000 4GB | 64GB DDR5-RAM |
| 92 | Apple M2 Pro | Apple M2 Pro | 16GB RAM |
| 94 | MacBook Pro | Apple M2 Pro (19 Core) | 32GB RAM |
| 98 | i5-13600K | RX6600 8GB | 32GB DDR5-RAM |
| 98 | Apple M3 Pro | Apple M3 Pro (12/18) | 36GB RAM |
| 106 | Apple M2 Pro | Apple M2 Pro | 32GB RAM |
| 112 | MacBook Pro 14,2" | Apple M1 Pro (10C/16C) | 16GB RAM |
| 116 | i7-11800H | RTX3050Ti 4GB Mobile | 32GB |
| 120 | MacBook Pro (2021) | Apple M1 Pro (8C/14C) | 16GB RAM |
| 122 | i5 (iMac 2020) | Radeon Pro 5300 4GB | 32GB RAM |
| 146 | i9-10940X | Intel ARC 770LE 16GB | 128GB DDR4-RAM |
| 146 | R9 3900X | GTX1080 8GB | 32GB DDR4-RAM |
| 160 | i7-1280P | RTX3050 Ti Mobile 4GB | 32GB RAM |
| 162 | Apple MacBook Air M2 | Apple M2 | 16GB RAM |
| 168 | Ryzen Threadripper 1920X | GTX1070 Ti 8GB | 32GB RAM |
| 172 | Apple Mac Mini M2 | Apple M2 | 24GB RAM |
| 176 | Apple MacBook Air M2 | Apple M2 | 8GB RAM |
| 178 | i7-6700K | GTX1660Ti 6GB | 16GB RAM |
| 182 | MacBook Air M2 | Apple M2 (10 Core GPU) | 16GB RAM |
| 190 | i9-9900K | RTX1070 8GB | 64GB RAM |
| 194 | R5 2600X | GTX1080 8GB | 32GB RAM |
| 200 | R7 6800H | RTX3050 Ti 4GB | 16GB DDR5-RAM |
| 204 | R9 5900X | GTX1660 6GB | 64GB DDR4 |
| 238 | R5 5600X | RX570 4GB | 32GB RAM |
| 246 | i7-1165G7 | Intel Iris Xe | 16GB RAM |
| 246 | i5-9300H | GTX1650 4GB | 16GB RAM |
| 248 | Mac Mini M1 | Apple M1 | 16GB RAM |
| 252 | MacBook Pro M1 | Apple M1 (8/8 Core) | 16GB RAM |
| 254 | MacBook Pro M1 | Apple M1 | 16GB RAM |
| 260 | i7-4790 | RX6400 4GB | 32GB DDR3-RAM |
| 284 | i7-9700K | GTX1060 6GB | 32GB DDR4-RAM |
| 300 | R7 6800H | iGPU | 16GB DDR5-RAM |
| 308 | R9 6900HX | iGPU | 32GB RAM |
| 512 | R7 7840HS | Radeon 780M (Mobile) | 16GB DDR5-RAM |
| 890 | R5 5625U | iGPU Vega7 | 16GB RAM |
| 918 | i7-1165G7 | Intel Iris Xe | 16GB RAM |
| 960 | R5 5600G | iGPU | 32GB DDR4-RAM |
| 974 | R5 7600X | Radeon Pro WX3100 4GB | 32GB RAM |
| 1500 | i7-13700K | iGPU (UHD 770) | 32GB RAM |
資料來源:LrC - Benchmark KI-Entrauschen
這麼長的表格大家肯定看的霧煞煞,而且又有 CPU/GPU/VRAM 三者交互,還有不同代數、不同硬體廠商的產品,那該怎麼解讀呢?首先先幫各位整理
- 一張圖片好歹也要 100 秒內完成,我想大部分人忍耐極限就到這裡了,因此 100 秒之後的數據可忽略
- 100 秒以上的基本上都是老舊顯卡、16GB RAM,以下的都是桌面級 GPU、32GB RAM -> 32GB RAM 是基本要求
- Mac M 系列處理器的優點只有低功耗運行,論執行時間的性價比不划算,且要 M1 Ultra/Max 以上速度才夠 -> 不常用 AI 功能的才選擇 M 系列,頂配的 M1 Ultra 速度夠快,但是單論執行時間性價比不划算
- AMD 的 GPU 也可流暢運行 PS/LR,但是考慮到 AI 生態系,毫無理由選擇 AMD GPU
- 頂配的不用看了,有錢人根本不用管表格性價比,他要考慮的是多顯卡、伺服器,這張表格對他沒有意義
現在我們已經篩選了五個條件了,因此表格只剩下這樣:
| 執行時間(秒) | CPU | GPU | RAM |
|---|---|---|---|
| 28 | R9 5900X | RTX4080 Super 16GB | 64GB |
| 30 | i7-14700K | RTX4070 Ti 12GB | 96GB |
| 30 | i9-12900K | RTX4070 Ti 12GB | 64GB |
| 30 | i5-12600K | RTX3080 10GB | 32GB |
| 30 | R9 5900X | RTX3080 Ti | 32GB |
| 32 | Threadripper 1950X | RTX4080 | 64GB |
| 32 | R7 5800X3D | RTX3080 Ti | 32GB |
| 32 | R7 5700X | RTX3080 12GB | 32GB |
| 36 | i9-9900K | RTX3080 10GB | 64GB |
| 36 | i5-13600K | RTX4070 12GB | 64GB |
| 36 | i7-13700K | RTX4070 12GB | 64GB |
| 36 | i7-14700KF | RTX4070 12GB | 64GB |
| 36 | R9 5900X | RTX3070 8GB | 64GB |
| 38 | R9 5900X | RTX4070 12GB | 64GB |
| 40 | i7-9700K | RTX4070 12GB | 64GB |
| 42 | i9-12900F | RTX3070 8GB | 32GB |
| 42 | i5-12600K | RTX3070 8GB | 32GB |
| 44 | i7-13700K | RTX4060 Ti 8GB | 64GB |
| 44 | i9-11900K | RTX3060 Ti 8GB | 64GB |
| 46 | i7-13700 | RTX4060 16GB | 128GB |
| 48 | R7 3800X | RTX3060 Ti 8GB | 32GB |
| 50 | R9 7950X | RTX4060 8GB | 96GB |
| 50 | i9-9900 | RTX2080 Super | 32GB |
| 52 | R7 7840HS | RTX4060 8GB | 16GB |
| 54 | i9-12900K | RTX3060 12GB | 32GB |
| 54 | i7-13700K | RTX3060 12GB | 64GB |
| 54 | i7-12700 | RTX3060 12GB | 64GB |
| 54 | i5-13600K | RTX4060 8GB | 32GB |
| 56 | i9-13900 | RTX3060 12GB | 32GB |
| 56 | R9 5900X | RTX3060 12GB | 32GB |
| 56 | i7-13700H | RTX4070 8GB Mobile | 16GB |
| 58 | R9 3900X | RTX3060 12GB | 64GB |
| 58 | R5 3600 | RTX2070 Super 8GB | 32GB |
| 58 | i7-13700H | RTX4060 8GB Mobile | 32GB |
| 58 | i7-12700H | RTX3060 6GB Mobile | 16GB |
| 60 | i9-9900K | RTX3060 12GB | |
| 66 | R9 5900X | Quadro RTX4000 8GB | 64GB |
| 70 | Xeon E5-2696 v4 | Quadro RTX4000 8GB | 64GB |
| 70 | R5 5600G | RTX3050 8GB | 32GB |
| 70 | i7-13700K | RTX2060 6GB | 32GB |
現在表格已經到可以肉眼觀察的階段了,繼續分析這張表格:
- 32GB RAM 是基本款也非常夠用,升級到 64 GB 沒有效能差異(54 秒 RTX3060 64GB vs. 56 秒 RTX3060 32GB,以及多個 RTX4060 時間差異)
- RAM 頻率、幾代毫無關係
- VRAM 至少 8GB 是基本款,升級到 16GB VRAM 不會加快處理時間
- CPU 對處理時間也有影響,但是必須基於 GPU 已經夠強的前提下(多個 RTX3080 和 RTX4070 時間差異)
- Quadro 卡在這裡沒有幫助
- 不同代 GPU 沒有顯著的效能差異
- 更新驅動可提升效能(爬論壇原文裡面有,在很後面有人講到)
- 甜蜜點在 3070,2026/05 二手價 7000-8000,每張圖約 40 秒
- 如只買新品,新世代 50 系列顯卡,執行時間可直接對照前代 40 系顯卡
- 新品甜蜜點變成 5060 8GB(2026/05 市價 13000),因 16 GB 沒有性能提升,5070(2026/05 市價 23000)加價一萬只快 20%
圖表
由於市價浮動、有些只有二手,因此比較市價沒有意義,而這幾代的 GPU 在 Adobe AI 降噪沒有顯著效能差異,3060/4060 或是 3070/4070 基本上效能一樣,於是 x 軸改用 CUDA 數為基準,CUDA 數也能側面反應最初的上市價格。
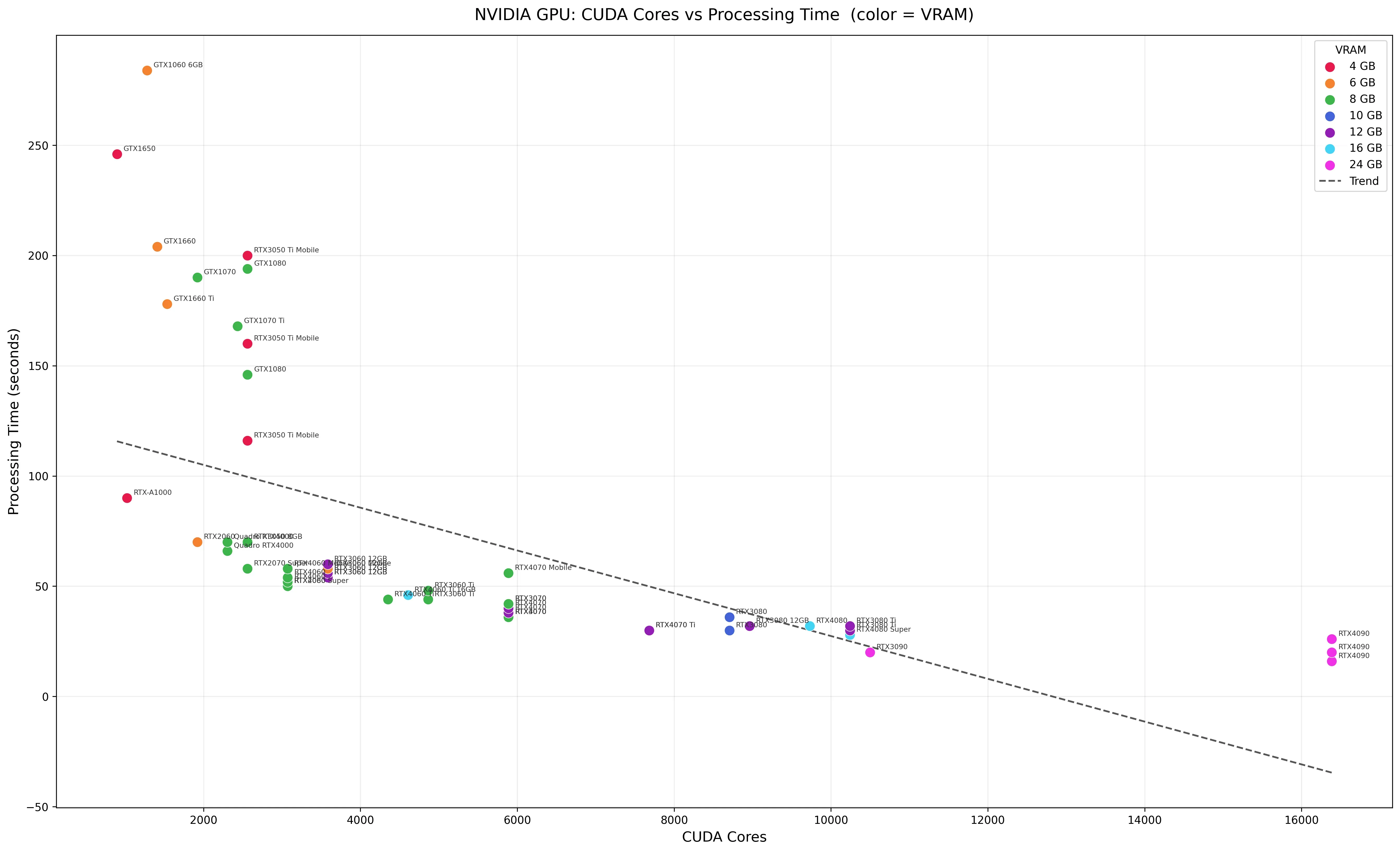
全部 NV 顯卡
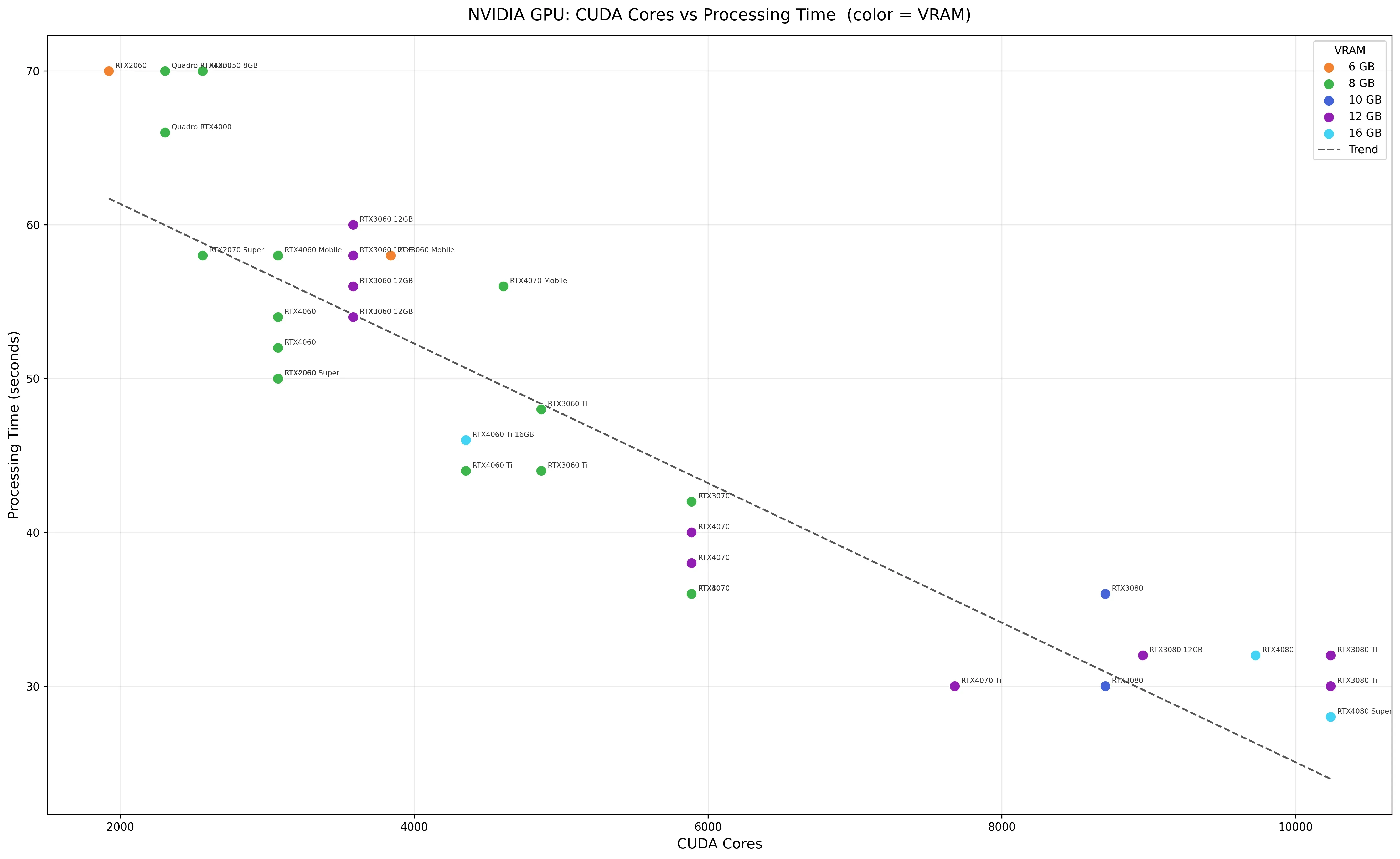
過濾後的 NV 顯卡
結論
結論還是看預算,性價比再高預算不到都沒用,預算有到位沒性價比一樣照買,簡單來說
- 傳統修圖:Ultra 5 已經足夠,有錢就上 Ultra 7。
- AI 降噪:新舊代 GPU 的效能沒有差別,最好是 Ultra 5 + 3070/5060,3070 效能甚至比 5060 高,但是二手就是賭博。
- AI 降噪:表格中的數據缺乏 Ultra 5 等級(約 5000-6000 價位的 CPU),但是透過少數數據觀察,影響不大,仍舊是 GPU 取勝,因此在 Ultra 5 以上的 CPU 的前提下, GPU 升級優先。
- 更低預算:有什麼就買什麼,基本上更低預算的完全沒得挑。
是否該買 16GB VRAM 版本的顯示卡?現階段不必要,但是不知道未來 AI 發展。LR 的建議是使用 16GB VRAM 顯卡,請見此討論。
- 圖表文字重疊的原因是兩組數據執行時間剛好一樣
- 嚴謹的說,第二段標題應該要說 AI denoise 而不是 AI 修圖
- 數據有差異的原因包含測試時電腦是否是 cold 狀態、驅動版本、Adobe 版本等等,不過還是大致能做個參考
參考連結:
- LrC - Benchmark KI-Entrauschen
- GPU Benchmark Denoise AI
- What is better for my new Photoshop/Lightroom PC - RTX 5070 with 12GB (192bit) or RTX 5060 Ti OC with 16GB (128bit)?
- GPU Specs Database
原始碼
繪圖原始碼可用 uv run filename.py 直接執行
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "matplotlib",
# "numpy",
# "pandas",
# ]
# ///
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# NVIDIA GPUs only, sourced from original table
# cores from TechPowerUp specs
data_all = [
{"time": 16, "gpu": "RTX4090", "cores": 16384, "vram": 24},
{"time": 20, "gpu": "RTX4090", "cores": 16384, "vram": 24},
{"time": 20, "gpu": "RTX3090", "cores": 10496, "vram": 24},
{"time": 26, "gpu": "RTX4090", "cores": 16384, "vram": 24},
{"time": 28, "gpu": "RTX4080 Super", "cores": 10240, "vram": 16},
{"time": 30, "gpu": "RTX4070 Ti", "cores": 7680, "vram": 12},
{"time": 30, "gpu": "RTX4070 Ti", "cores": 7680, "vram": 12},
{"time": 30, "gpu": "RTX3080", "cores": 8704, "vram": 10},
{"time": 30, "gpu": "RTX3080 Ti", "cores": 10240, "vram": 12},
{"time": 32, "gpu": "RTX4080", "cores": 9728, "vram": 16},
{"time": 32, "gpu": "RTX3080 Ti", "cores": 10240, "vram": 12},
{"time": 32, "gpu": "RTX3080 12GB", "cores": 8960, "vram": 12},
{"time": 36, "gpu": "RTX3080", "cores": 8704, "vram": 10},
{"time": 36, "gpu": "RTX4070", "cores": 5888, "vram": 12},
{"time": 36, "gpu": "RTX4070", "cores": 5888, "vram": 12},
{"time": 36, "gpu": "RTX4070", "cores": 5888, "vram": 12},
{"time": 36, "gpu": "RTX3070", "cores": 5888, "vram": 8},
{"time": 38, "gpu": "RTX4070", "cores": 5888, "vram": 12},
{"time": 40, "gpu": "RTX4070", "cores": 5888, "vram": 12},
{"time": 42, "gpu": "RTX3070", "cores": 5888, "vram": 8},
{"time": 42, "gpu": "RTX3070", "cores": 5888, "vram": 8},
{"time": 44, "gpu": "RTX4060 Ti", "cores": 4352, "vram": 8},
{"time": 44, "gpu": "RTX3060 Ti", "cores": 4864, "vram": 8},
{"time": 46, "gpu": "RTX4060 Ti 16GB", "cores": 4608, "vram": 16},
{"time": 48, "gpu": "RTX3060 Ti", "cores": 4864, "vram": 8},
{"time": 50, "gpu": "RTX4060", "cores": 3072, "vram": 8},
{"time": 50, "gpu": "RTX2080 Super", "cores": 3072, "vram": 8},
{"time": 52, "gpu": "RTX4060", "cores": 3072, "vram": 8},
{"time": 54, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 54, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 54, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 54, "gpu": "RTX4060", "cores": 3072, "vram": 8},
{"time": 56, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 56, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 56, "gpu": "RTX4070 Mobile", "cores": 5888, "vram": 8},
{"time": 58, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 58, "gpu": "RTX2070 Super", "cores": 2560, "vram": 8},
{"time": 58, "gpu": "RTX4060 Mobile", "cores": 3072, "vram": 8},
{"time": 58, "gpu": "RTX3060 Mobile", "cores": 3584, "vram": 6},
{"time": 60, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 66, "gpu": "Quadro RTX4000", "cores": 2304, "vram": 8},
{"time": 70, "gpu": "Quadro RTX4000", "cores": 2304, "vram": 8},
{"time": 70, "gpu": "RTX3050 8GB", "cores": 2560, "vram": 8},
{"time": 70, "gpu": "RTX2060", "cores": 1920, "vram": 6},
{"time": 90, "gpu": "RTX-A1000", "cores": 1024, "vram": 4},
{"time": 116, "gpu": "RTX3050 Ti Mobile", "cores": 2560, "vram": 4},
{"time": 146, "gpu": "GTX1080", "cores": 2560, "vram": 8},
{"time": 160, "gpu": "RTX3050 Ti Mobile", "cores": 2560, "vram": 4},
{"time": 168, "gpu": "GTX1070 Ti", "cores": 2432, "vram": 8},
{"time": 178, "gpu": "GTX1660 Ti", "cores": 1536, "vram": 6},
{"time": 190, "gpu": "GTX1070", "cores": 1920, "vram": 8},
{"time": 194, "gpu": "GTX1080", "cores": 2560, "vram": 8},
{"time": 200, "gpu": "RTX3050 Ti Mobile", "cores": 2560, "vram": 4},
{"time": 204, "gpu": "GTX1660", "cores": 1408, "vram": 6},
{"time": 246, "gpu": "GTX1650", "cores": 896, "vram": 4},
{"time": 284, "gpu": "GTX1060 6GB", "cores": 1280, "vram": 6},
]
data_filtered = [
{"time": 28, "gpu": "RTX4080 Super", "cores": 10240, "vram": 16},
{"time": 30, "gpu": "RTX4070 Ti", "cores": 7680, "vram": 12},
{"time": 30, "gpu": "RTX4070 Ti", "cores": 7680, "vram": 12},
{"time": 30, "gpu": "RTX3080", "cores": 8704, "vram": 10},
{"time": 30, "gpu": "RTX3080 Ti", "cores": 10240, "vram": 12},
{"time": 32, "gpu": "RTX4080", "cores": 9728, "vram": 16},
{"time": 32, "gpu": "RTX3080 Ti", "cores": 10240, "vram": 12},
{"time": 32, "gpu": "RTX3080 12GB", "cores": 8960, "vram": 12},
{"time": 36, "gpu": "RTX3080", "cores": 8704, "vram": 10},
{"time": 36, "gpu": "RTX4070", "cores": 5888, "vram": 12},
{"time": 36, "gpu": "RTX4070", "cores": 5888, "vram": 12},
{"time": 36, "gpu": "RTX4070", "cores": 5888, "vram": 12},
{"time": 36, "gpu": "RTX3070", "cores": 5888, "vram": 8},
{"time": 38, "gpu": "RTX4070", "cores": 5888, "vram": 12},
{"time": 40, "gpu": "RTX4070", "cores": 5888, "vram": 12},
{"time": 42, "gpu": "RTX3070", "cores": 5888, "vram": 8},
{"time": 42, "gpu": "RTX3070", "cores": 5888, "vram": 8},
{"time": 44, "gpu": "RTX4060 Ti", "cores": 4352, "vram": 8},
{"time": 44, "gpu": "RTX3060 Ti", "cores": 4864, "vram": 8},
{"time": 46, "gpu": "RTX4060 Ti 16GB", "cores": 4352, "vram": 16},
{"time": 48, "gpu": "RTX3060 Ti", "cores": 4864, "vram": 8},
{"time": 50, "gpu": "RTX4060", "cores": 3072, "vram": 8},
{"time": 50, "gpu": "RTX2080 Super", "cores": 3072, "vram": 8},
{"time": 52, "gpu": "RTX4060", "cores": 3072, "vram": 8},
{"time": 54, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 54, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 54, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 54, "gpu": "RTX4060", "cores": 3072, "vram": 8},
{"time": 56, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 56, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 56, "gpu": "RTX4070 Mobile", "cores": 4608, "vram": 8},
{"time": 58, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 58, "gpu": "RTX2070 Super", "cores": 2560, "vram": 8},
{"time": 58, "gpu": "RTX4060 Mobile", "cores": 3072, "vram": 8},
{"time": 58, "gpu": "RTX3060 Mobile", "cores": 3840, "vram": 6},
{"time": 60, "gpu": "RTX3060 12GB", "cores": 3584, "vram": 12},
{"time": 66, "gpu": "Quadro RTX4000", "cores": 2304, "vram": 8},
{"time": 70, "gpu": "Quadro RTX4000", "cores": 2304, "vram": 8},
{"time": 70, "gpu": "RTX3050 8GB", "cores": 2560, "vram": 8},
{"time": 70, "gpu": "RTX2060", "cores": 1920, "vram": 6},
]
for data, filename in [(data_all, "cuda_vs_time_all.png"), (data_filtered, "cuda_vs_time_filtered.png")]:
df = pd.DataFrame(data)
vram_palette = {
4: "#e6194b",
6: "#f58231",
8: "#3cb44b",
10: "#4363d8",
12: "#911eb4",
16: "#42d4f4",
24: "#f032e6",
}
z = np.polyfit(df["cores"], df["time"], 1)
p = np.poly1d(z)
x_line = np.linspace(df["cores"].min(), df["cores"].max(), 300)
fig, ax = plt.subplots(figsize=(18, 11))
plotted_vram = set()
for _, row in df.iterrows():
vram = int(row["vram"])
color = vram_palette[vram]
label = f"{vram} GB" if vram not in plotted_vram else None
ax.scatter(row["cores"], row["time"],
s=90, color=color, edgecolors="white",
linewidths=0.5, zorder=3, label=label)
plotted_vram.add(vram)
ax.plot(x_line, p(x_line),
color="#555555", linewidth=1.6, linestyle="--",
label=f"Trend",
zorder=2)
for _, row in df.iterrows():
ax.annotate(
row["gpu"],
xy=(row["cores"], row["time"]),
xytext=(6, 3),
textcoords="offset points",
fontsize=6.5,
color="#333333",
)
ax.set_title("NVIDIA GPU: CUDA Cores vs Processing Time (color = VRAM)", fontsize=15, pad=14)
ax.set_xlabel("CUDA Cores", fontsize=13)
ax.set_ylabel("Processing Time (seconds)", fontsize=13)
handles, labels = ax.get_legend_handles_labels()
vram_pairs = sorted(
[(h, l) for h, l in zip(handles, labels) if "GB" in l],
key=lambda x: int(x[1].split()[0])
)
trend_pairs = [(h, l) for h, l in zip(handles, labels) if "Trend" in l]
sh, sl = zip(*(vram_pairs + trend_pairs))
ax.legend(sh, sl, title="VRAM", fontsize=10, title_fontsize=10)
ax.grid(True, alpha=0.25)
plt.tight_layout()
plt.savefig(filename, dpi=300, bbox_inches="tight")